Fusion-Reflection
self-supervised learning
May, 1993
Brandyn Webb /
brandyn@sifter.org
Presentation preferences and category: Oral, Algorithms & Architectures, Learning Algorithms
This is a brief summary of the paper entitled "Fusion-Reflection"
The paper addresses, in the broadest terms, the inherent limitations of both supervised and "traditional" unsupervised algorithms, and proposes that a change in metaphor-from performance enhancement to knowledge acquisition-can overcome these limitations. Stochastic modeling efficacy is proposed as an empirical measure of knowledge, providing a concrete and mathematical means of "acquiring knowledge" via gradient ascent. A specific modeling architecture is described, and its evaluation and learning laws are derived. Experimental results are given for a hand-printed character-recognition task.
By using the "total knowledge" of the system (as measured by modeling efficacy, in this case) to define the learning gradient, a number of problems are avoided. In particular, since even the earliest stages of abstraction represent knowledge, such a system has guidance from the ground up. This is in contrast to a typical task-performance gradient, which may well be flat for a randomly-initialized network tackling a difficult problem (since there may be a great deal of prerequisite knowledge required before the task performance can even begin improving). On the other hand, "total knowledge" also encompasses global conceptual relationships-mandating, for instance, the distinction between the hand-printed letters "O" and "Q", not because of their visual differences (indeed, they may be more similar than two renditions of "A"), but because of their participation in higher abstractions (words).
The specific architecture presented, Furf-I, is a hierarchical super-set of node-labeled Hidden Markov Models. The network is organized as a hierarchy of node groups. Although a two-group, recurrent Furf network is equivalent to an HMM, recurrent topologies are not specifically discussed in this paper. Instead, the focus is on the hierarchical treatment of static patterns, with emphasis on the principle of Fusion-Reflection-the fusion of low-level information into higher level abstractions, and the subsequent reflection of the gained information to refine learning at the lower levels. The evaluation and learning laws are, to some extent, incremental, hierarchical analogs of the Baum-Welch forward-backward algorithm, and are remarkably simple:
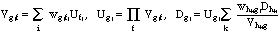 - Evaluation Law
- Evaluation Law
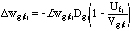 - Learning Law
- Learning Law
where f, g, and h are the input, current, and output groups, and i, j, and k are the respective input, current, and output node indices within each of those groups; L is the learning rate; V is a partial product, U is "upward activation" at a node, and D is "downward activation" at a node. In the paper, these equations are derived in probabilistic notation; they are presented here in their functional forms for clarity.
Being a model, a Furf-I network can generate exemplar patterns. More usefully, the evaluation law presented in the paper can act as a classification algorithm, a pattern-likelihood assessor, and as a pattern-completion algorithm. Similarly, the learning law can operate in both supervised and unsupervised modes. The empirical studies demonstrate both unsupervised and supervised learning of categories, as well as pattern completion using the trained network. It is of particular interest that the network was able to abstract contextual information during unsupervised learning, and to use this information to significantly improve its context-free recognition accuracy. Additionally, both theoretical and empirical evidence suggest that learning time varies at worst linearly with respect to the number of layers, which is a vast improvement over many current multi-layer algorithms.
The data used for the empirical studies consisted of about 9,000 lower-case, hand-printed letters from a single writer, rendered with anti-aliasing into a 12x12, two-bit deep image. This relatively easy corpus was selected because certain limitations of the Furf-I architecture prevent it from easily learning transformational and style invariance. (Although the path to overcoming these limitations seems clear, the behavior of the existing architecture has been sufficiently interesting as to supersede that pursuit for the moment.) No separation of training and testing data was made, but since the majority of the learning often happened within the first epoch, it was not a pressing issue (as pattern evaluation, which provides performance statistics, always precedes pattern training). The corpus was derived from written English text, and was always presented in order, including the separating spaces (which brought the actual epoch size to nearly 12,000).
The basic topology used for the empirical studies was a three-layer network, beginning with the 12x12x4 input layer, through a 3x3x18 middle layer, to a 28 node output group. Unsupervised training produced a classification accuracy of 87%-in some trials reaching 65% before the end of the first epoch. Supervised training reached nearly 94% within the first epoch, eventually leveling out at 96%. Human performance on this data set is approximately 95% (this relatively informal measurement used one "untrained" subject, who had not studied this particular corpus beforehand).
The topology was then enhanced with two time-delayed copies of the output group, and a fourth layer of 60 nodes, above the now 3x28 output layer. Unsupervised training of this network with delays disabled produced the expected 87% (identical to the results obtained by the simpler architecture). Enabling the delays increased the final accuracy to over 91%. After training, disabling the delays decreased accuracy by only a couple tenths of a percent-producing a final single-letter recognition accuracy of nearly 91%. It appears that the network was able to discover bi- and tri-gram statistics from only the temporal sequence of letter images, and to use these statistics to enhance its ability to identify individual letters.
To test pattern completion, the code was modified to accept a textual representation of the image, so that various types of noise could be easily added by hand. A set of degraded patterns evaluated with the Furf network were reconstructed remarkably well (although, the test patterns were taken from amongst the training set). The following is an actual example of reconstruction; the question marks represent ambiguous inputs:
### ###
?????????????? #####
? ## .#. ## .#.
?+#+ ## ## +#+ ## ##
??## ## ## ## ## ##
???????? # ## # #
+#+# ? # +#+# #
+### ????? +### #
+### #? +### #
?????????? #? ### #
+##. ? #? +##. #
+## ? #? +## #
+## ? .#? +## .#
+#????? ##? +# ##
+#? ##? +# ##
+#????????? +##
+# +#
+# +#
.# .#
This summary was submitted to
NIPS
in may, 1993. They responded with a single, hand-scribbled note that said:
Architecture is unclear--a picture is sometimes worth
1000 words! Too many sweeping generalizations--e.g., how do you know n-gram
stats were learned from the data? Please be more specific as to what you
are actually doing.
Full paper, ~20 pages, is available in postscript (~136K)
as Furf-I.ps
and pdf (~92K) as Furf-I.pdf.
Brandyn Webb /
brandyn@sifter.org

since April 26, 1996